> Include or exclude files and directories for searching that match the given glob. This always overrides any other ignore logic. Multiple glob flags may be used. Globbing rules match .gitignore globs. Precede a glob with a ! to exclude it. If multiple globs match a file or directory, the glob given later in the command line takes precedence.
As an extension, globs support specifying alternatives: -g 'ab{c,d}*' is equivalent to -g abc -g abd. Empty alternatives like -g 'ab{,c}' are not currently supported. Note that this syntax extension is also currently enabled in gitignore files, even though this syntax isn't supported by git itself. ripgrep may disable this syntax extension in gitignore files, but it will always remain available via the -g/--glob flag.
> When this flag is set, every file and directory is applied to it to test for a match. For example, if you only want to search in a particular directory foo, then -g foo is incorrect because foo/bar does not match the glob foo. Instead, you should use -g 'foo/*'.
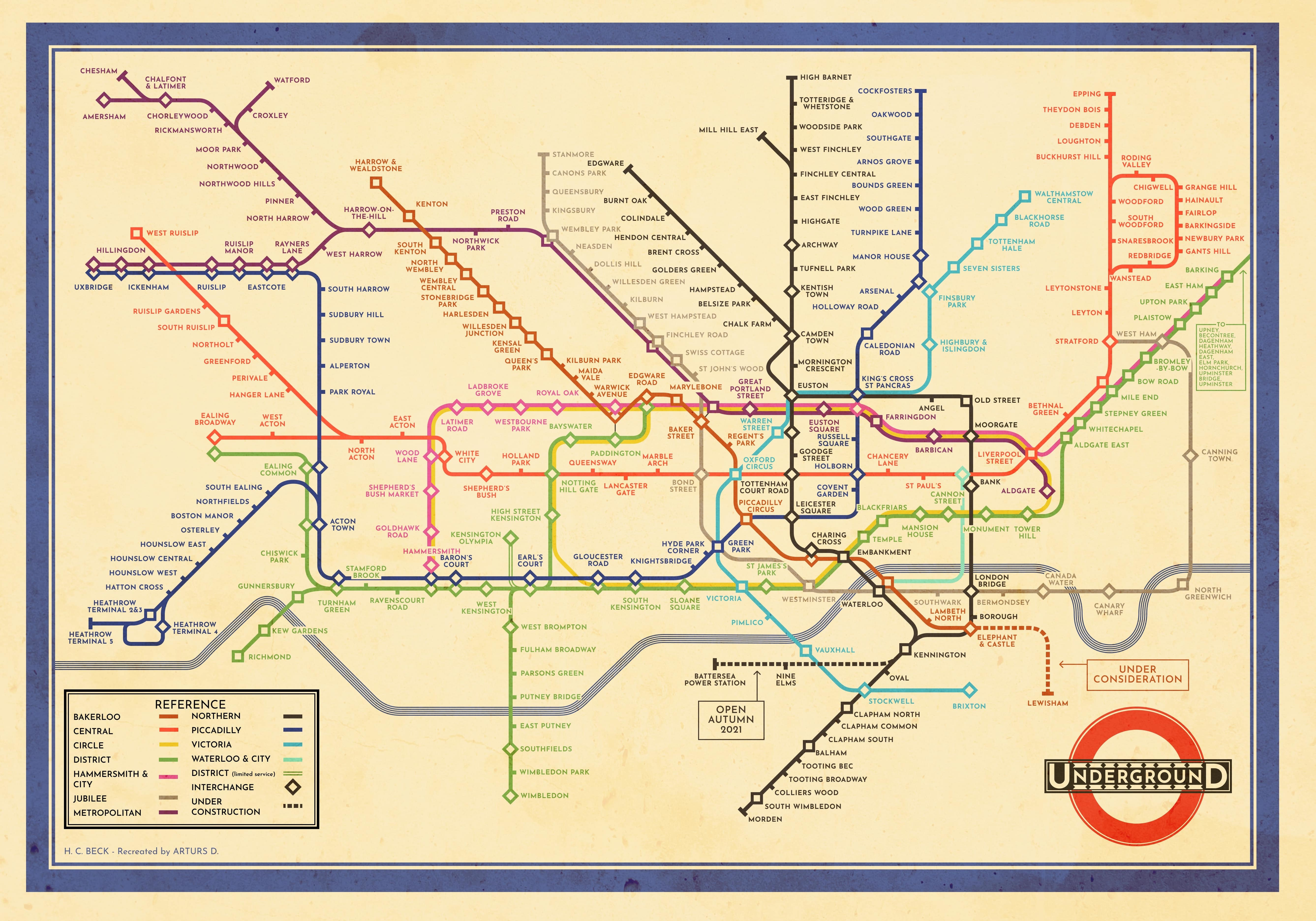
which contains Heathrow Terminals 1, 2, 3, 4 & 5 on the Picadilly line. For about 15 seconds I imagined a world where Heathrow has had 5 terminals since 1933, then I read the map itself: "Recreated by Arthurs D". Phew.
Awesome example of improving information conveyance through abstractions though!
The thing about dogfooding is that you have to force it in many domains, and if you aren't careful it can push you towards solving issues your users don't actually have.
We've found ourselves trying to find this balance on Tritium. It's a word processor for lawyers, so has a specific narrow domain that allows us to provide a differentiated experience from Word. But if we try to use it like Word, we end up wanting generalized features that don't fit that strategy. I wrote a little about what we've come up with here: https://tritium.legal/blog/eat.
This is one of the compelling rationales for closed-source / commercial software in certain B2B SAAS domains. It seems like you just cannot adequately test the happy and sad paths from a QA perspective in FOSS unless it's (1) insanely successful or (2) a dev tool.
Just in time for everyone and their brother to vibe code a docx editor. This doesn't make much sense except as a token gesture that will make everyone's life worse.
[Edit: I work on a Word competitor for lawyers. If anyone here thinks this type of move does anything but further entrench someone like Microsoft who has the resources to implement every format under the sun, I’ve got some news for you. So if it’s not anti-monopolistic, then what? Do you actually think the User prefers it? Honestly?
The world standardizes on VHS two decades ago. How is mandating betamax going to benefit anyone other than the established players and box ticking bureaucrats?]
Do you mean an ODF/.odt editor? Why vibe code them? they already exist. MS Office can open ODF files now. The British government has been using ODF for most files exchanged with the public (e.g. downloads from gov.uk) for many years now with no issues I know of.
The point is that compliance around docx has become a commodity. Now that you have to support 2 formats with your application, that is orders of magnitude more complex.
In your roadmap you listed pdf support, so hopefully your system already has abstractions in place to handle multiple input formats without rewriting everything, no? You'll just have to pull-in an odf crate (or vibe code one).
I understand that it's extra work for you, but if you take a step back and look around you maybe you'd see the greater good.
Yes, we support reading .doc, .pdf and read/write on .docx. Perhaps there is some greater good here, but I can tell you it's a burden for at least one competitor in the ecosystem. We basically cannot market into Germany now until we've baked this in. This certainly doesn't hurt Microsoft.
Then of course maybe that isn't the point which is fine. I'm actually surprised at people reporting on here that ODF is their preferred format. I've worked professionally in documents for two decades and never come across one other than as accidental output from Libreoffice. So perhaps it is my ignorance on display and Germany never was a viable market without this.
That's really interesting. I'm a lawyer, and I had always interpreted the license like a ToS between the developers. That (in my mind) meant that the license could impose arbitrary limitations above the default common law and statutory rules and that once you touched the code you were pregnant with those limitations, but this does make sense. TIL. So, thanks.
Does the reasoning in the cases where people to whom GPL software was distributed could sue the distributor for source code, rather than relying on the copyright holder suing for breach of copyright strengthen the argument that arbitrary limitations are enforceable?
Licenses != contracts, and well, the FSF's position has always been that the GPL isn't a contract, and contracts are what allow you to impose arbitrary limitations. Most EULAs are actually contracts.
Yes... a license can be granted via contract. I think the question here is whether posting a LICENSE.md file in a public github repo forms a contract (offer, acceptance, consideration) when a developer uses it. If so, I'm back to being unclear how "public domain" can really play a role. The developer is bound by the terms of that contract.
I am working on a sub 100KLOC Rust application and can't productively use the agentic workflows to improve that application.
On the other hand, I have tried them a number of times in greenfield situations with Python and the web stack and experienced the simultaneous joy and existential dread of others. They can really stand new projects up quick.
As a founder, this leaves me with what I describe as the "generation ship" problem. Is it possible that the architecture we have chosen for my project is so far out of the training data that it would be faster to ditch the project and reimplement it from scratch in a Claude-yolo style? So far, I'm convinced not because the code I've seen in somewhat novel circumstances is fairly mid, but it's hard to shake the thought.
I do find chatting with the models incredibly helpful in all contexts. They are also excellent at configuring services.
If what you are doing is novel then I don't think yolo'ing it will help either. Agents don't do novel.
I've even noticed this in meeting summaries produced by AI:
A prioritisation meeting? AI's summary is concise, accurate, useful.
A software algorithm design meeting, trying to solve a domain-specific issue? AI did not understand a word of what we discussed and the summary is completely garbled rubbish.
If all you're doing is something that already exists but you decided to architecture it in a novel way (for no tangible benefit), then I'd say starting from scratch and make it look more like existing stuff is going to help AI be more productive for you.
Otherwise you're on your own unless you can give AI a really good description of what you are doing, how things are tied together etc.
And even then it will probably end up going down the wrong path more often than not.
I’m a UX designer not a coder, but this is so bizarre to me because shouldn’t every project be doing something novel? Otherwise why does it exist? If this industry is so full of people independently writing the same stuff that AI can replicate it…then it was a vast misallocation of resources to begin with.
I'm surprised there's no more attempts to stablize around a base model, like in stable diffusion, then augment those models with LoRas for various frameworks, and other routine patterns. There's so much going into trying to build these omnimodels, when the technology is there to mold the models into more useful paradigms around frameworks and coding patterns.
Especially, now that we do have models that can search through code bases.
Sure, I work in security, and the amount of sub-6 month old companies with SOC2 reports are mind-boggling. The trend started probably a year ago or at least I noticed it. There is seemingly no oversight of AICPA to enforce any kind of standard in practice, companies like Delve are hiring vibe-auditors to autogenerate the reports. You already had the issue with low-cost providers like A-Scend who have maybe one qualified auditor across 5 auditing teams or so (I worked with them several times) - but at least they had several rounds of human-QA before issueing any kind of report. A company that started 6 months ago simply cannot in any meaningful way prove that they should be trusted, because they cannot prove that their processes are solid. And that's fine and normal, you have early adopters and companies with not-so-critical data for these use cases. Getting some vibe audited reports early on is setting you up for distrust, it's a signal that you are willing to take all short cuts to get enterprise customers and that's a red flag.
Ha, yes I didn't even consider it meant anything other than corporate private credit. Otherwise we'd be talking about presumably mortgages or "consumer debt". Right?
{kind=link}
reply